理解 OpenAI - Responses API
OpenAI 最近推出了 Responses API,用于取代原有的 Chat Completions API,在其基础上封装了更多功能、简化了开发过程。这份笔记主要涵盖了 Responses API 的主要优势。
1. 省钱
聊天对话中,无需每个请求携带历史消息,很大程度减少了 token 的消耗,越多轮对话效果越明显,因为 Responses API 是有状态的。

2. 内置工具
记得原先需要自己写代码通过 function calling 调用第三方 API 获取搜索结果,再回传给 LLM 生成最终结果,现在 web_search 直接内置了,请求当中包含 tools: [ { type: "web_search_preview" } ] 就完事了。
举个例子,通过以下几行代码,你就可以问最新股价了。
1 | import OpenAI from "openai"; |
通过 Logs 你可以看到 web_search tool 被使用: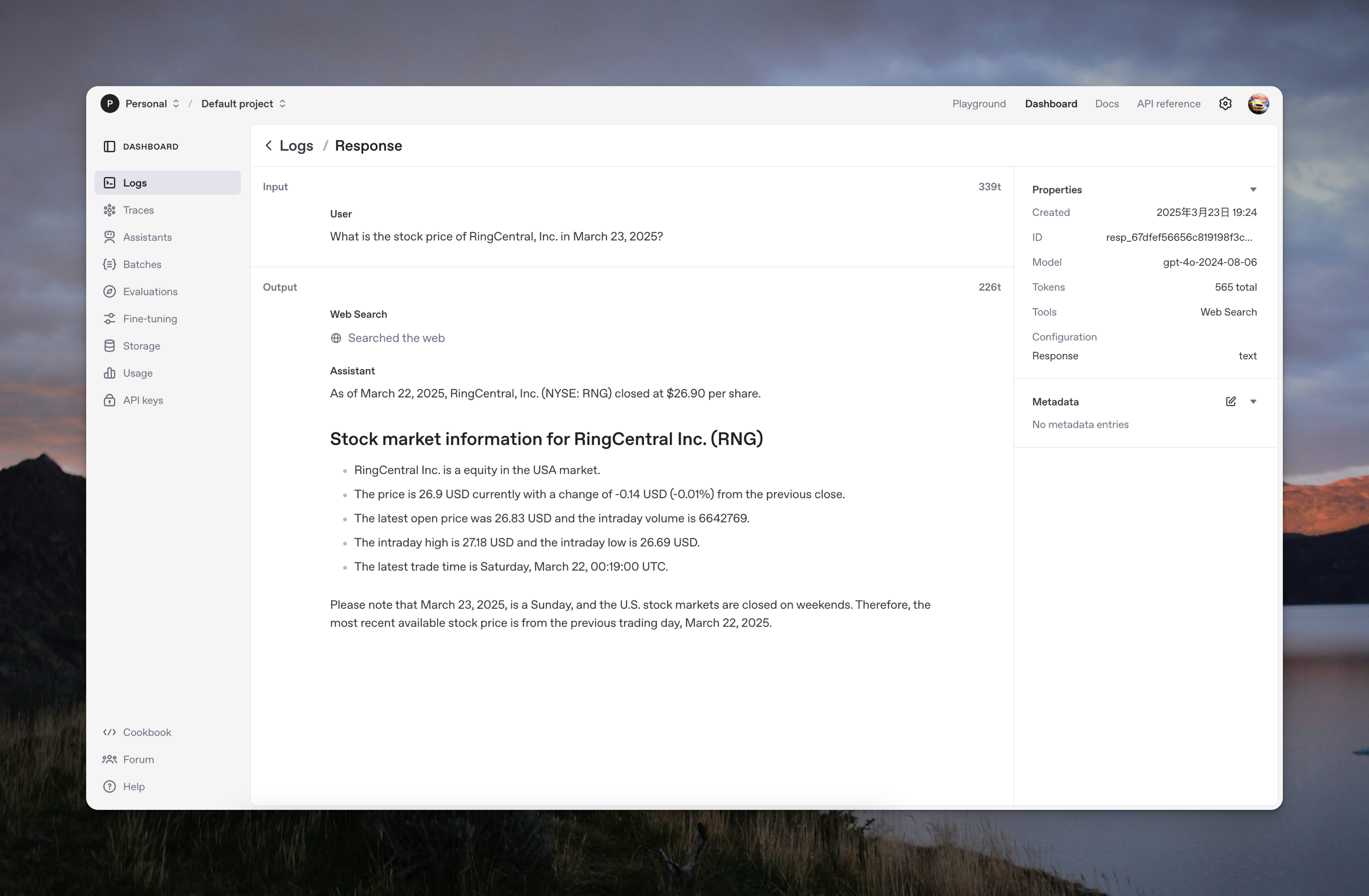
在 API 返回体中,你可以拿到哪个网页被用于生成结果 1: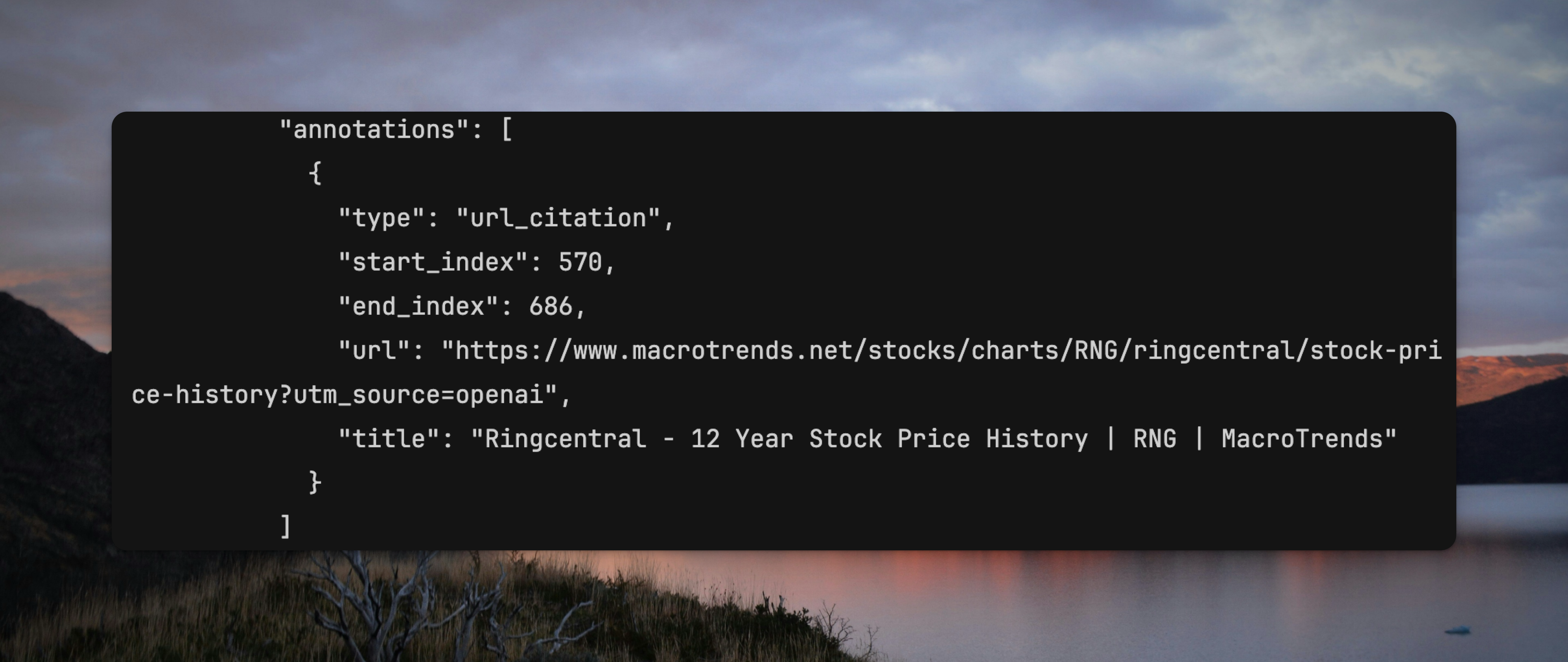
除了 web_search,内置的工具还有 file_search 和 computer_use,预计 code_interpreter 也将很快得到支持。
相信未来会有越来越多应用层的功能被内置到大模型的 API 当中,AI 应用的开发将会变得更简单。
